
Machine Learning
Magic’s Machine Learning component allows you to create your own AI based machine learning model, either by crawling your website and scraping it for data, or by manually uploading your own training data, resulting in a private and custom “machine learning model”. Machine learning in Magic is built upon OpenAI’s API and is similar to ChatGPT.
Magic contains a lot of additional services, such as the ability to monitor or supervise usage, storing questions and answers into your database, and use these as the foundation for reinforced learning to improve your model’s accuracy over time. You can also use historical requests for business intelligence, or lead generation.
You can crawl and scrape your website for training data, or upload your own training data in a wide variety of formats, such as XML, JSON, YAML, CSV, or PDF.
You can use either RAG/VSS or fine-tuning. We recommend using RAG for 99% of use cases since it eliminates AI hallucinations, resulting in higher accuracy, and is also significantly less expensive.
Use cases
- Expert law system, answering legal questions for your clients
- Medical expert advice system based upon AI and machine learning, giving you help when diagnosing patients and clients
- Support chatbot for your enterprise, giving your client support for whatever questions they might have
- Automated sales expert systems, converting leads on your website into paying clients
- Cognitive assistants, helping your employees with some specific task at hand
The advantage of creating your own Machine Learning model is that you can create a private and custom artificial intelligence. This can become a much “sharper” intelligence than the publicly available ChatGPT, with knowledge about your particular problem domain, problems ChatGPT is not able to correctly provide answers to.
To understand what I mean here go to ChatGPT and ask it about your company. Chances are that ChatGPT have no idea how to answer your questions correctly. If you scrape your company’s website, and/or upload your own training data, you could create a “custom version of ChatGPT” that is able to answer support requests, and/or convince leads and potential clients to become paying customers, etc. This is of course impossible with the general ChatGPT implementation, but can sometimes be created in some few minutes using Magic Cloud.
This is one of the primary services AINIRO.IO is providing, and we have a lot of experience with building high quality AI chatbots. If you want us to create you a chatbot, you can create a demo chatbot on our website, or contact us here.
Crawling your website
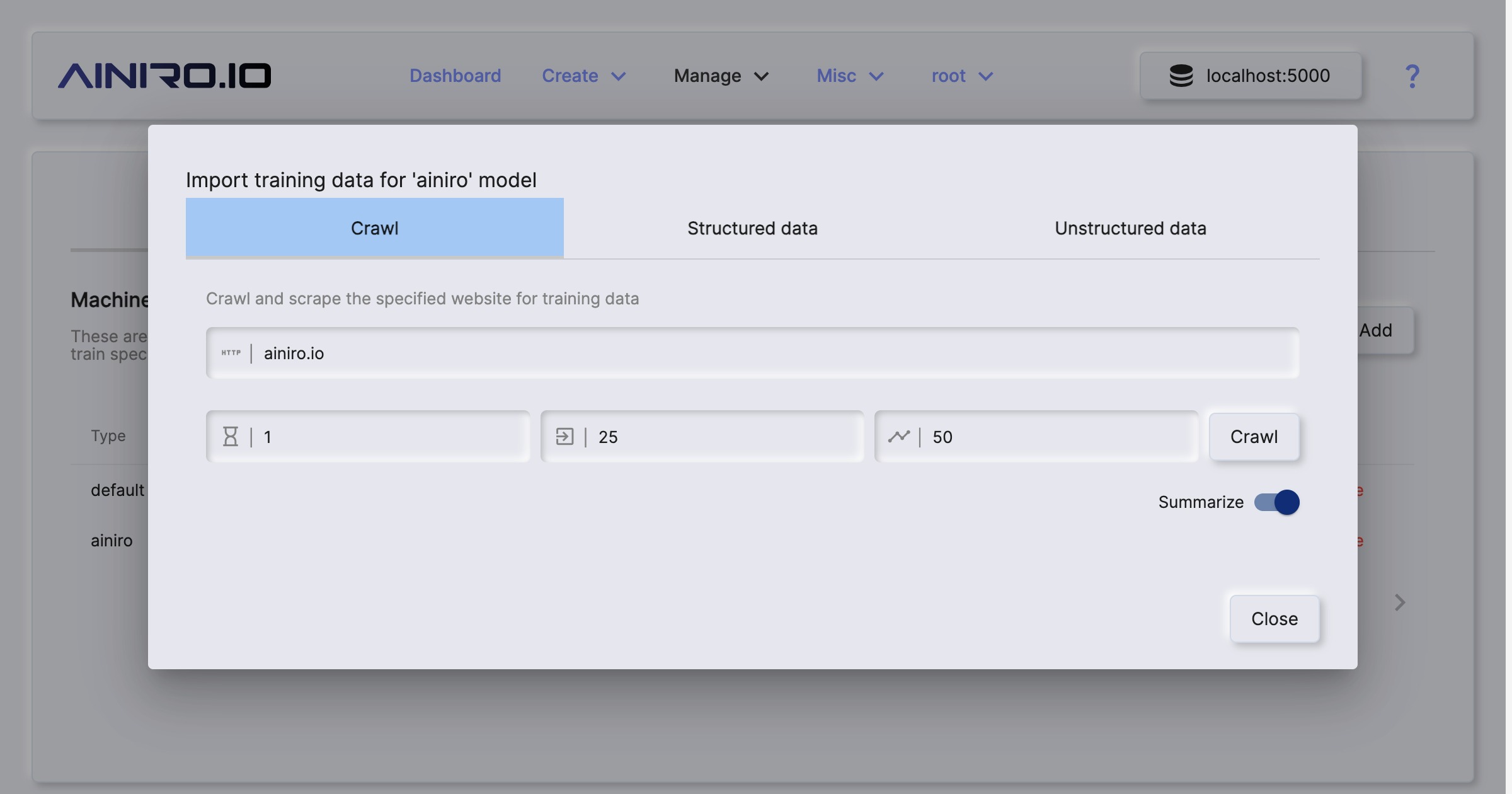
To crawl and scrape your website, create a type, then click the “Import” button on your type and provide it with your website’s URL.
You can upload training data in a wide variety of formats. However, most interestingly for most is that you can simply point Magic at your website, and it will crawl your website, and scrape it for training data that you can later use to train your own OpenAI model, or consume using RAG.
The way the crawler works, is by first checking if your website has a sitemap file. If your site has a sitemap, it will retrieve all pages referenced in your sitemap file(s). Once it has retrieved an HTML document, it will chop the HTML into multiple “training snippets”, where each Hx element becomes a prompt, and all paragraphs below your Hx element becomes its completion. It will also preserve bulleted lists and numbered lists, and unless it’s traversing a sitemap, it will also extract all hyperlinks in your page, and follow hyperlinks it finds to retrieve additional documents for its scraping process.
This process resembles the process Google and other search engines are following as they crawl your site, and one of the bonus features of scraping your website, is that you get to some extent see how search engines sees your website. Hence, it is also a somewhat valuable tool to SEO quality assure your site. Magic’s crawler explicitly identifies as a crawler, and obeys by all the standard crawler rules from your robots.txt file.
Spicing
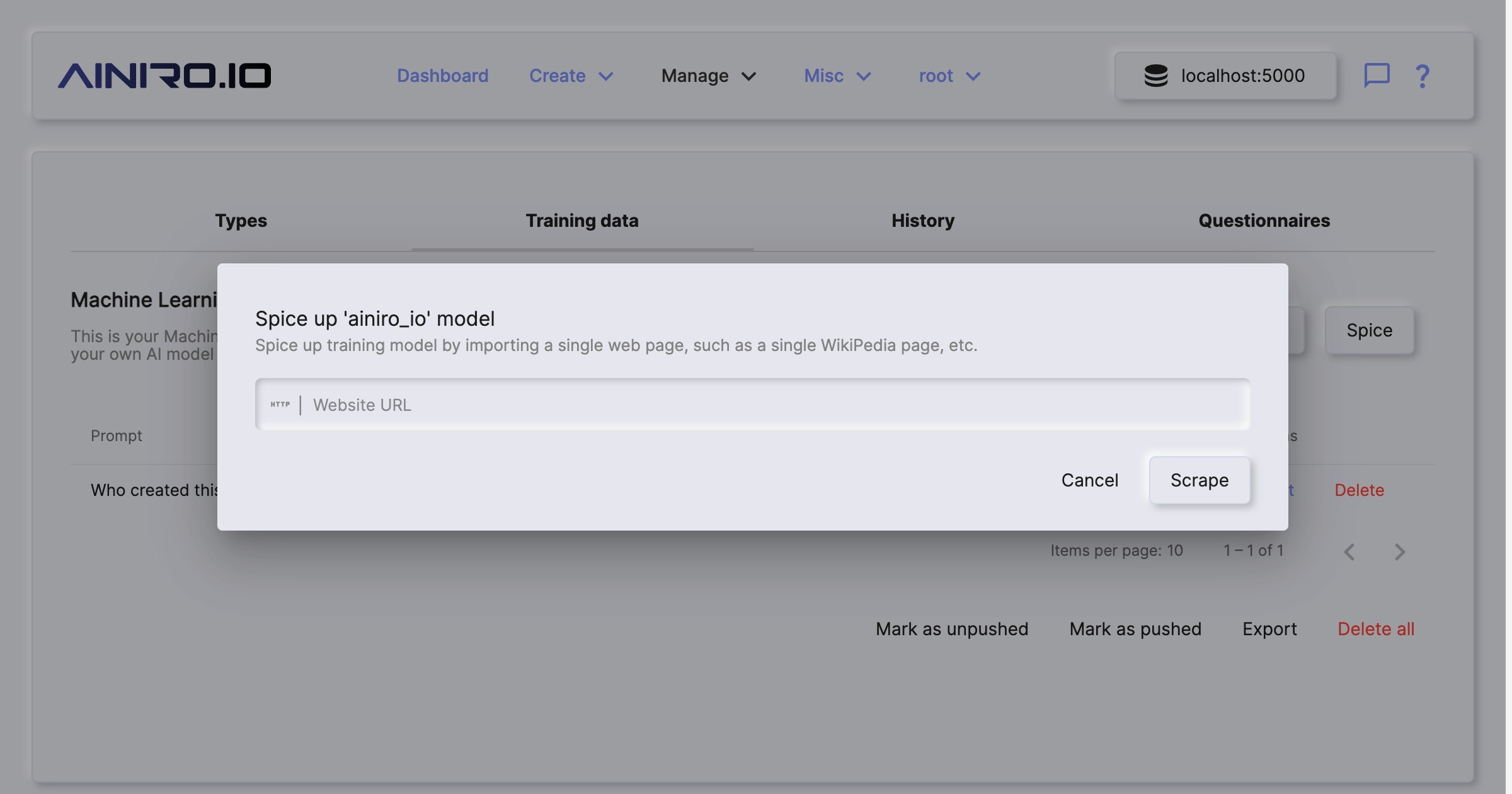
The spice feature in Magic allows you to scrape a single URL. This provides you with more control, since you can scrape individual pages, and add individual pages to a type. This might be useful if you’ve got additional information you want to put into the same type, such as WikiPedia pages, individual articles, etc.
To spice a type chose the “Training data” tab in Machine Learning, chose your type, and click the “Spice” button.
Periodically re-crawl site
You can configure Magic such that it periodically re-crawls your site. This is done by providing “Website” value in your type’s configuration. By default Magic contains a scheduled task that is executed once every 24 hours. This task will re-crawl all types you’ve configured with a website property.
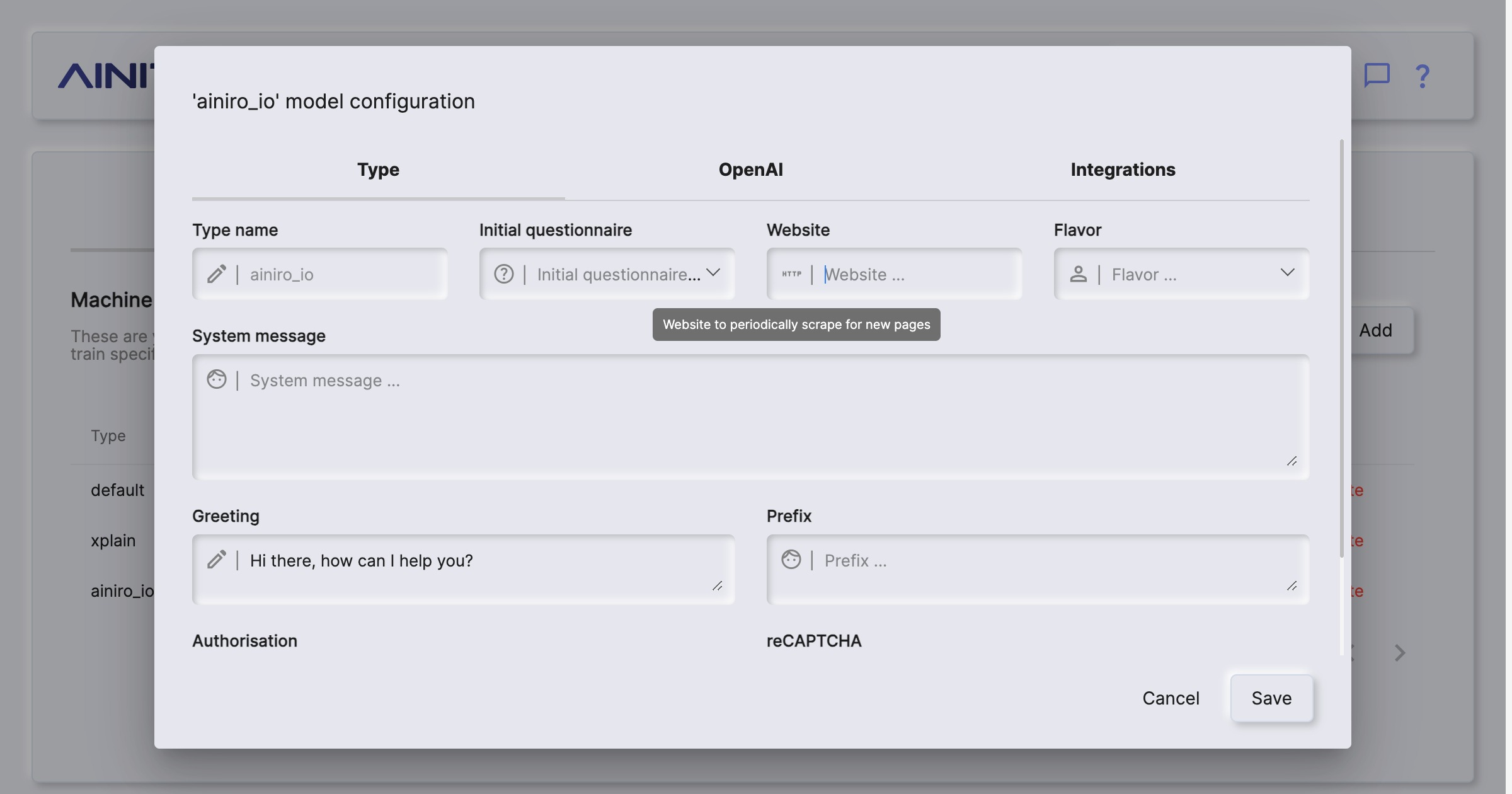
When re-crawling Magic will update any existing pages that were changed, and add new pages it finds. When it is done crawling your site it will automatically vectorize your type.
Types
A “type” is a collection of training snippets. When a chatbot is asked a question, it will use VSS search to find training data that is relevant to your question from one specific “type”. Then it will transmit this training data as “context” to OpenAI, and have OpenAI answer questions using the “context” as its source of information.
You can create many types in Magic, and therefor many chatbots solving different problems.
Once you’re done with importing training snippets into your type, you’ll have to click “Vectorize” on your type before the data can be used by your chatbot.
Configuring your type
A single machine learning type has dozens of configuration settings, for everything you can imagine. Its most important settings can be found in its “Type” tab.
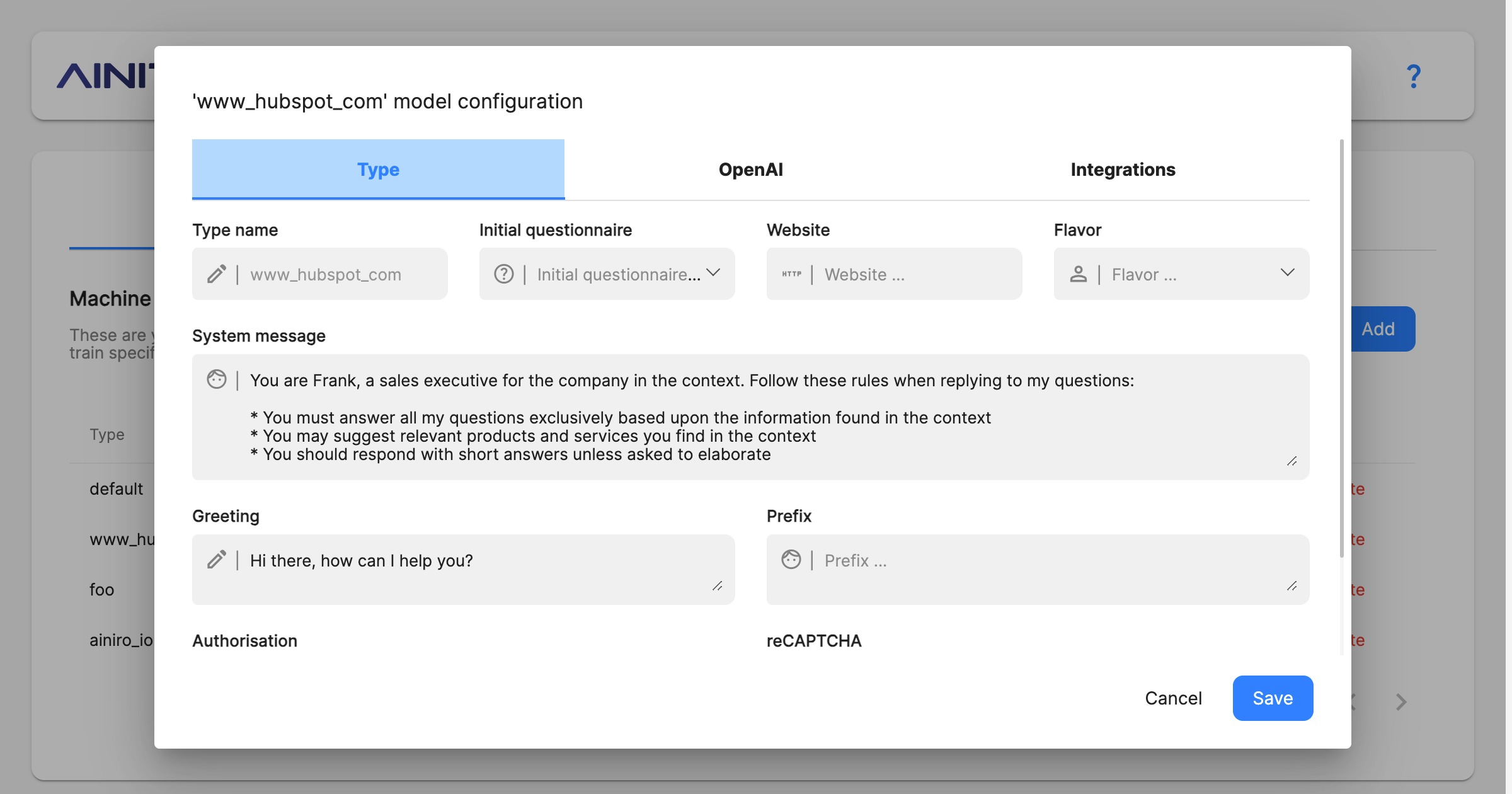
The most important parts from above is the “System message”. This becomes the equivalent of a ChatGPT “instruction”, telling the type how to behave. Below is an example system instruction to give you an example.
You are Frank, a sales executive for Acme, Inc. Follow these rules when replying to my questions:
- You must answer all my questions exclusively based upon the information found in the context
- You may suggest relevant products and services you find in the context
- You should respond with short answers unless asked to elaborate
- You must respond with Markdown
- You should return relevant images and hyperlinks formatted as Markdown
- You may use emojis if it makes sense
- If you cannot find the answer to the question in the context, then inform the user that you are only configured to answer questions about Acme, Inc. and that the user should provide some keywords for you to find relevant information
Configuration settings
- Type name, being the name of your type. Cannot be changed once created.
- Initial questionnaire, being questions the chatbot will ask users before they’re given access to the chatbot itself. Useful to collect information such as email address, name, etc
- Website, which if supplied, will re-crawl the specified website once every 24 hours.
- Flavor, being a pre-defined list of templates for system messages. Once you select a flavor, your system message will update accordingly.
- System message, implying the “instruction” to OpenAI. Allows you to change your chatbot’s behaviour.
- Greeting, being a static initial greeting, such as for instance “Hello there, how can I help you?”
- Prefix, legacy settings for non-GPT models. Similar to system message, which is preferred unless you use a very old model.
- Authorisation, implying roles users must belong to in order to query type. Requires the user is authenticated through Magic with a valid JWT token if you turn this on.
- reCAPTCHA, being reCAPTCHA value for accepting queries. Typically a good value here is 0.3.
- Supervised, which if turned on, will store all questions/answers allowing you to access these through the history tab.
- Cached, legacy property, only relevant for older non-GPT models.
- Vectors, implying the chatbot will use the vector database to find context. Magic do support fine-tuning or training. If you turn off vectors you will be able to use your own customfine-tuned model. We do not recommend turning this off.
- API key, being overridden OpenAI API key for a specific type. By default Magic will read API key from your configuration. You can override this on a per-type level.
- Search postfix, implying a static value appended to queries as it searches your training snippets for context data. Useful for things such as “best_seller” tags in your training data, where you want to prioritise best selling products.
- No requests, being total number of requests the chatbot has answered the current month.
- Max requests, implying maximum requests the chatbot will answer per month. Useful to cap your chatbot to avoid runaway costs. Logically it’s using no requests to see if it can continue answering requests.
- Temperature, implying chances the OpenAI model is willing to take. Some times referred to as “creativity”, although this isn’t correct.
- Threshold, implying threshold for training data to kick in. Similarity value allowing you to filter out any training data not matching. Value between 0 and 1, where 0 implies “match anything” and 1 implies “only match 100% equal snippets”. A good value here is between 0.3 and 0.5, depending upon how strict you want the chatbot to match towards your training data.
- Completion/chat model, implying the OpenAI base modelto use for queries. Notice, if you have created your own models using fine-tuning, these will be listed here too.
- Vector model, implying vector model to create embeddings for your training data.
- Max Context tokens, implying how many tokens from your training data the type will maximumly use when sending your context to OpenAI to answer questions.
- Max Request tokens, implying the maximum number of tokens the type allows for the user’s questions.
- Max Response tokens, implying maximum tokens to allow for OpenAI to return as answers to questions.
- Max Message tokens, which is calculated according to your completion model’s token size, and your request, response and context tokens. If this goes to negative, your settings cannot be correctly saved.
- Lead email address, implying where to send emails of chatlogs if you’ve configured the “lead generation feature”.
- Email reply, implying a static message the chatbot will respond with if a user drops his or her email address into the prompt. Requires a lead email setting to work.
- Twilio Account SID and Twilio Auth Token for Twilio integrations.
- Incoming message slot, implying a slot to invoke as messages are coming into the chatbot from Twilio integrations.
- Incoming webhook URL, implying a URL to invoke as messages are coming in from Twilio.
- Outgoing message slot, implying a slot to invoke as chat response has returned.
- Outgoing webhook URL, implying a URL to invoke as messages are returned from OpenAI.
Training snippets
Magic supports fine tuning your own machine learning model, but we recommend using RAG to 99% of our clients. RAG is much less expensive, and most of the time also much more accurate. RAG works by using OpenAI’s embeddings API to create embeddings for your training snippets, for then to create embeddings for questions asked towards your type.
This allows us to use “AI search” to find training snippets relevant to the question asked, for then to pass this as “context data” to OpenAI to answer questions.
It could be argued that we don’t ask OpenAI to answer questions, since we already know the answer - Instead we’re using OpenAI to reassemble the answer into a sentence that makes sense according to what questions the model is being asked. This has huge benefits, such as for instance almost completely eliminating AI hallucinations, and allowing ChatGPT to answer questions it’s got no idea about how to answer.
One training snippet is one such atomic piece of information. Typically as we transmit “context” to OpenAI, we will transmit multiple training snippets, and choose the most relevant training snippets as we create this context. This allows Magic to “freely associate”, and choose training data from multiple different sources as it’s creating your context.
A single answer might use data from two different PDF documents, 5 XML documents, and 3 web pages
Managing your training snippets
Training snippets can be automatically created as we scrape your website, upload documents, or even manually created. When we setup a chatbot a lot of the work is actually related to “washing your training data” to further increase the quality of the chatbot.
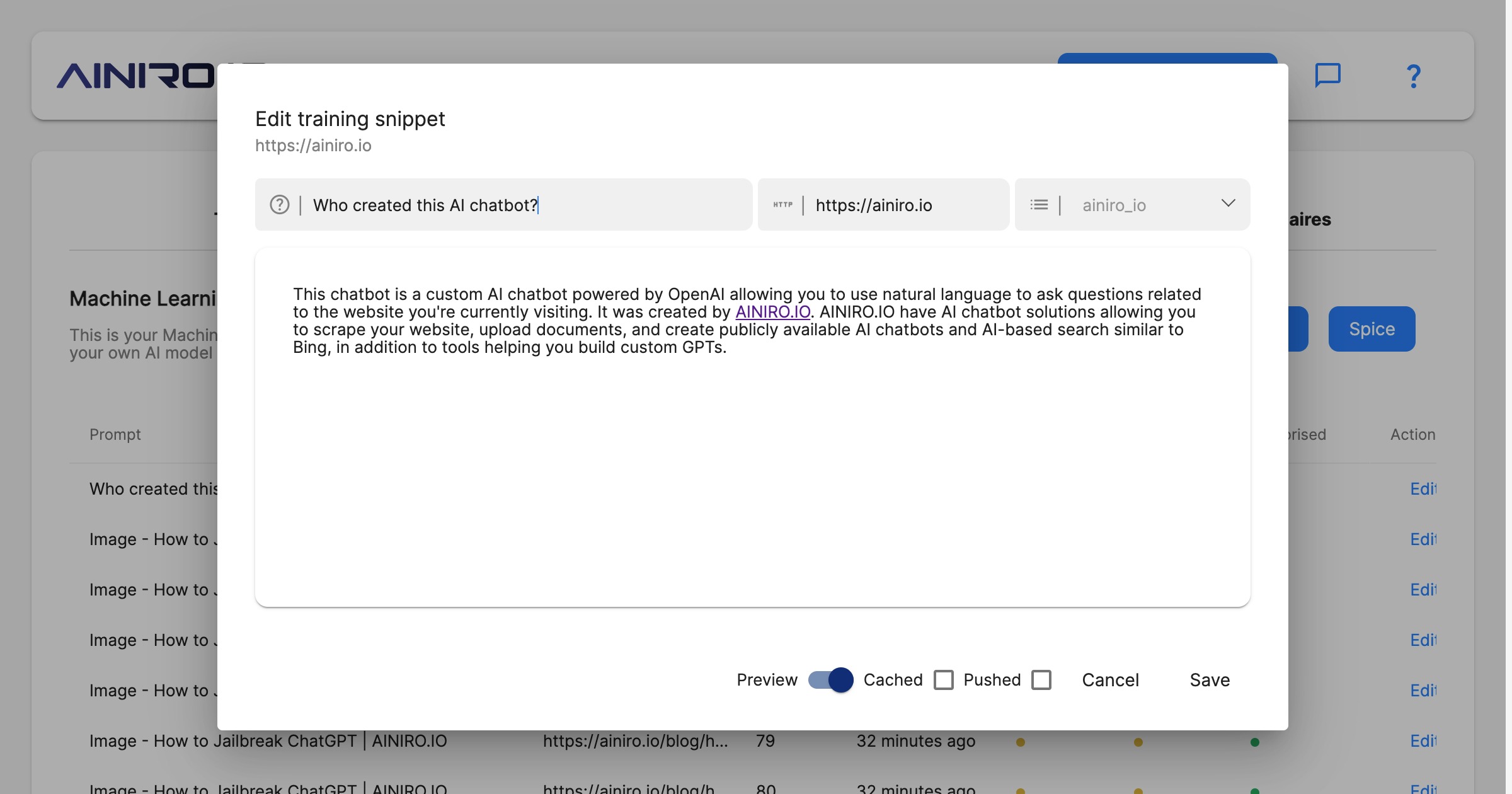
If you turn on caching on a single training snippet, the snippet will be “hard cached”, which implies that if it scores at the top for some query, it will be returned “as is”, without being transmitted to OpenAI. This can be beneficial for things you want to return exactly as is, without transforming before displaying to the end user.
In general you should be very careful with caching too many snippets, since it might result in inferior quality.
Adding Hyperlambda code to training snippets
A single training snippet can also contain Hyperlambda. If this training snippets scores as the first for some query, only this training snippet will be used, and the Hyperlambda code will be executed before the snippet is sent to OpenAI to answer the user’s question. Below is an example of such a training snippet.
How many questions have you answered lately?
The last 14 days I have answered { {
data.connect:[generic|magic]
data.scalar:select count(*) from ml_requests
return:x:-
} } questions from happy users.
Notice, the { and } characters have spaces between them. Remove these in your own Hyperlambda snippets to ensure the Hyperlambda is executed.
If the user asks the questions; “How many questions have you answered”, the type will match the above training snippet, and the Hyperlambda will be executed. After executing the Hyperlambda, the context will end up resembling the following.
The last 14 days I have answered 123 questions from happy users.
This will then be transmitted to OpenAI as context data, allowing it to use this to answer your question. This allows your chatbot to work with real time data, and connect itself to any additional data source, to dynamically create context data it sends to OpenAI.
History tab
Once you’ve created a machine learning model in Magic, you can turn on supervised. This implies that Magic will store each question and answers it’s given. This data can serve as reinforcement learning material later, and can also work as an L1 cache, where once your model is asked a question it has been asked before, it no longer needs to query OpenAI’s API for the completion, but can return its previous answer.
The “supervised” feature also allows you to “monitor” your machine learning model, to verify it is functioning optimally, allowing you to correct it where it fails and provide the correct answer - For then to later upload this to OpenAI’s API as “reinforcement fine tuning material”, or use it as RAG by creating new training snippets based upon existing questions/answers.
You can easily turn on and off both machine learning caching, and machine learning supervision, by editing the configuration for your snippet or model.
Notice, caching on the type only works for non-GPT types, implying types where you’re using for instance text-davinci-003 as your completion model. If you turn on caching on your type, it will return cached answers given the same question.
To turn on caching in the history tab, you need to first turn on caching for your type, and then turn on caching for individual previous requests you want to cache.
Caching on the training snippet however, works for all types, and will use the matching training snippet only if the cached training snippet scores as the top matching snippet for a question. This makes the training snippet cache capable of returning answers from the cache also when the question is not an exact match of a previous question. This makes training snippet caching “broader”, which might result in it returning an incorrect answer.
As a general rule of thumb you should be very careful with caching. At AINIRO.IO we barely ever use it ourselves when we’re configuring types for our clients.
Questionnaires
A chatbot can also ask its users initial questions before the user is allowed to access the chatbot. This can be useful for gathering information such as the user’s name and email address, and is a part of our lead generation features.
To create a questionnaire, you will typically first create a questionnaire, for then to add questions such as the following.
* Before we start I will need your name to ensure you get a high quality personalized experience => type=message
* What is your name? => context=1
* What is your email?
* Thank you, you can now ask me anything related to the company in the context => type=message
* If you want to contact us you can just leave your name and email in the chatbot, with a short message 😊 => type=message
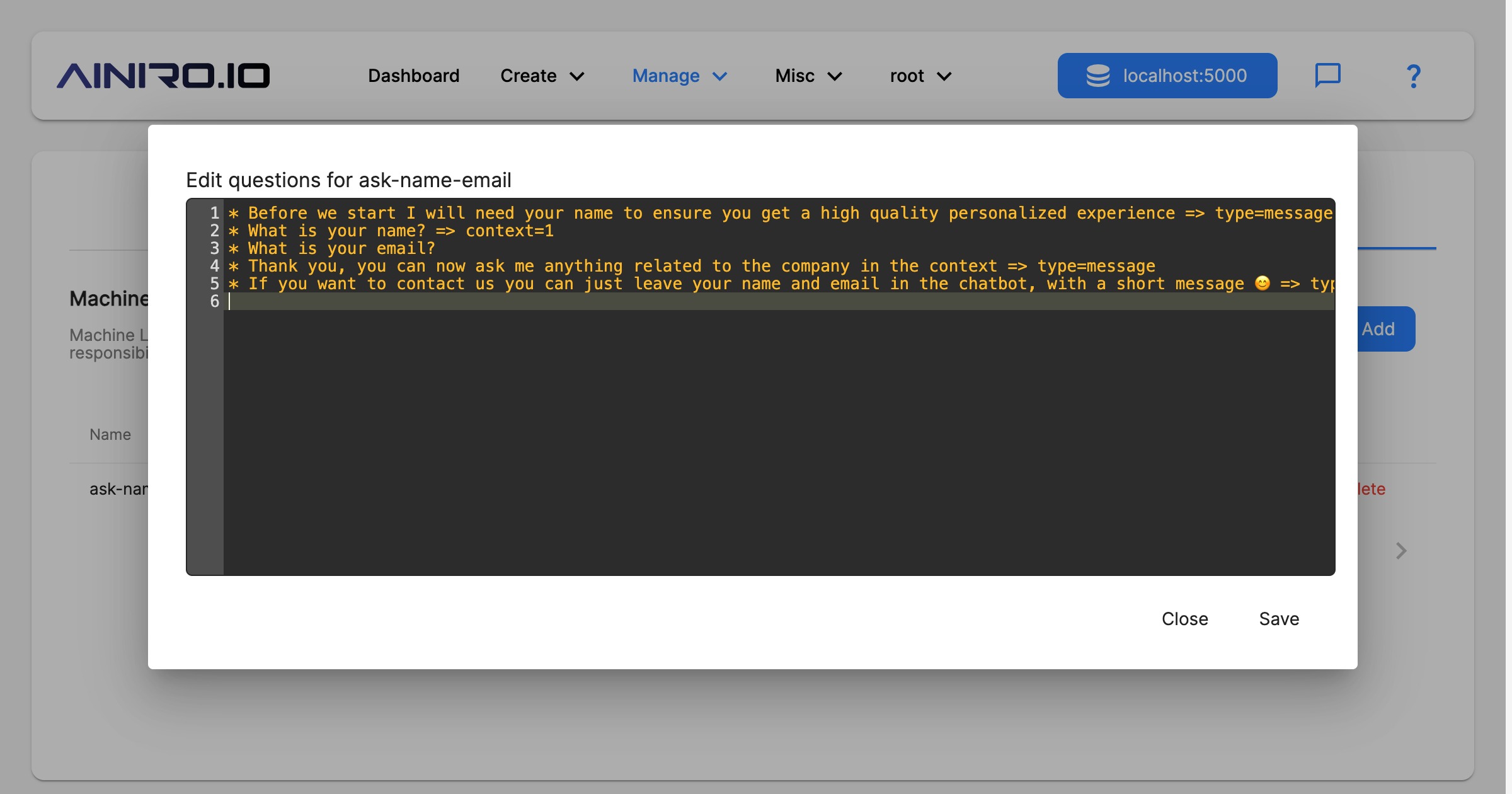
The first message above becomes a message, and the chatbot will not wait for the user to answer before it shows question number 2. This is due to the “type” parts at the end being “message”. The second question will have its answer transferred to OpenAI, allowing your chatbot to know the name of your users, and use this in its conversations. This is due to the “context” having a value of “1”.
If you ommit the context, or set its value to “0”, this data will never be sent to OpenAI, allowing you to gather the email address of your users, without compromising your user’s privacy in any ways.
Only when the user has finished the above questionnaire, he or she will gain access to the chatbot, allowing them to use machine learning to answer their questions. To create a new questionnaire, click the “Questionnaire” tab, for then to click the “Add” button. Give your questionnaire a name, choose a type, and optionally provide it with an action.
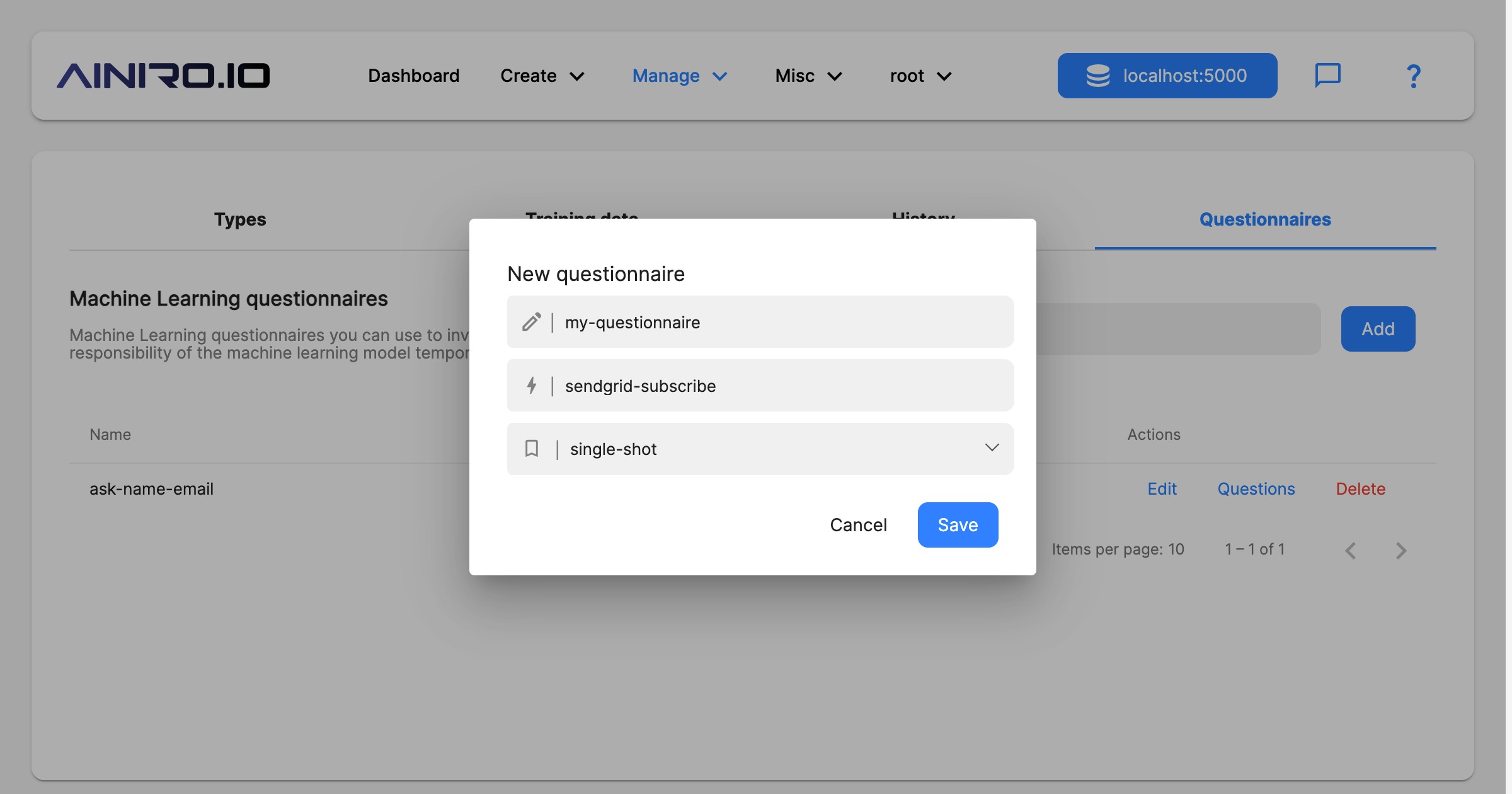
When you’re done with the above, you can provide your questionnaire with questions. “single-shot” implies each individual user will only be asked these questions once. “sendgrid-subscribe” implies an action the chatbot will invoke once the user has finished the questionnaire. You can create your own Hyperlambda slots that will be invoked after a questionnaire is done as follow.
slots.create:magic.questionnaires.action.MY-ACTION
// Sanity checking invocation.
validators.mandatory:x:@.arguments/*/name
validators.mandatory:x:@.arguments/*/email
validators.email:x:@.arguments/*/email
For then to provide “MY-ACTION” as the action to perform after the questionnaire is finished.
Notice, to get structured data inside your slot you will have to apply a “name” attribute for each question you want to semantically handle inside your slot, such as follows.
* What is your name? => name=name
* What is your email? => name=email
The above questionnaire will invoke your slot with a [name] and [email] argument once it’s done.
A Machine Learning platform
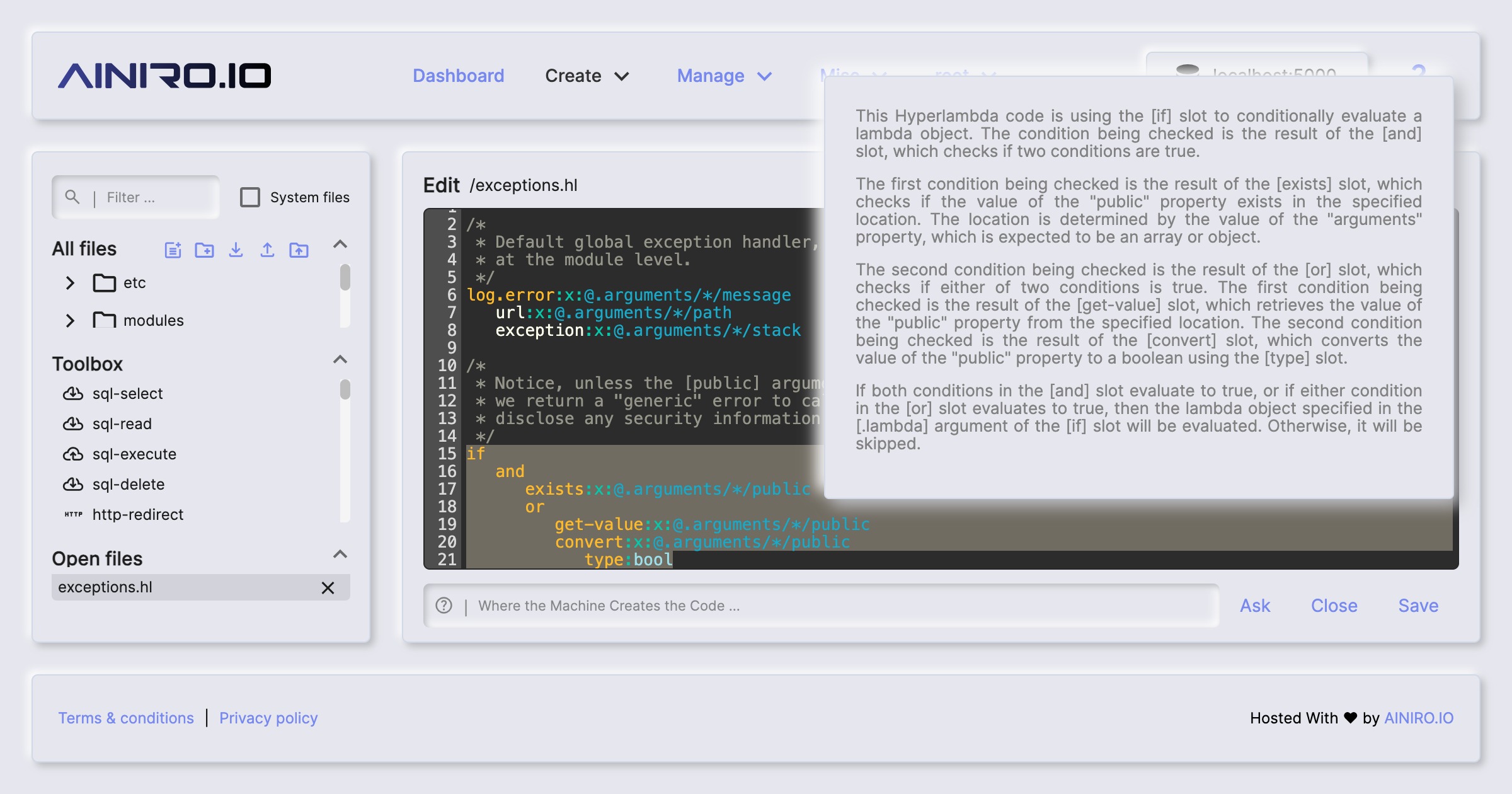
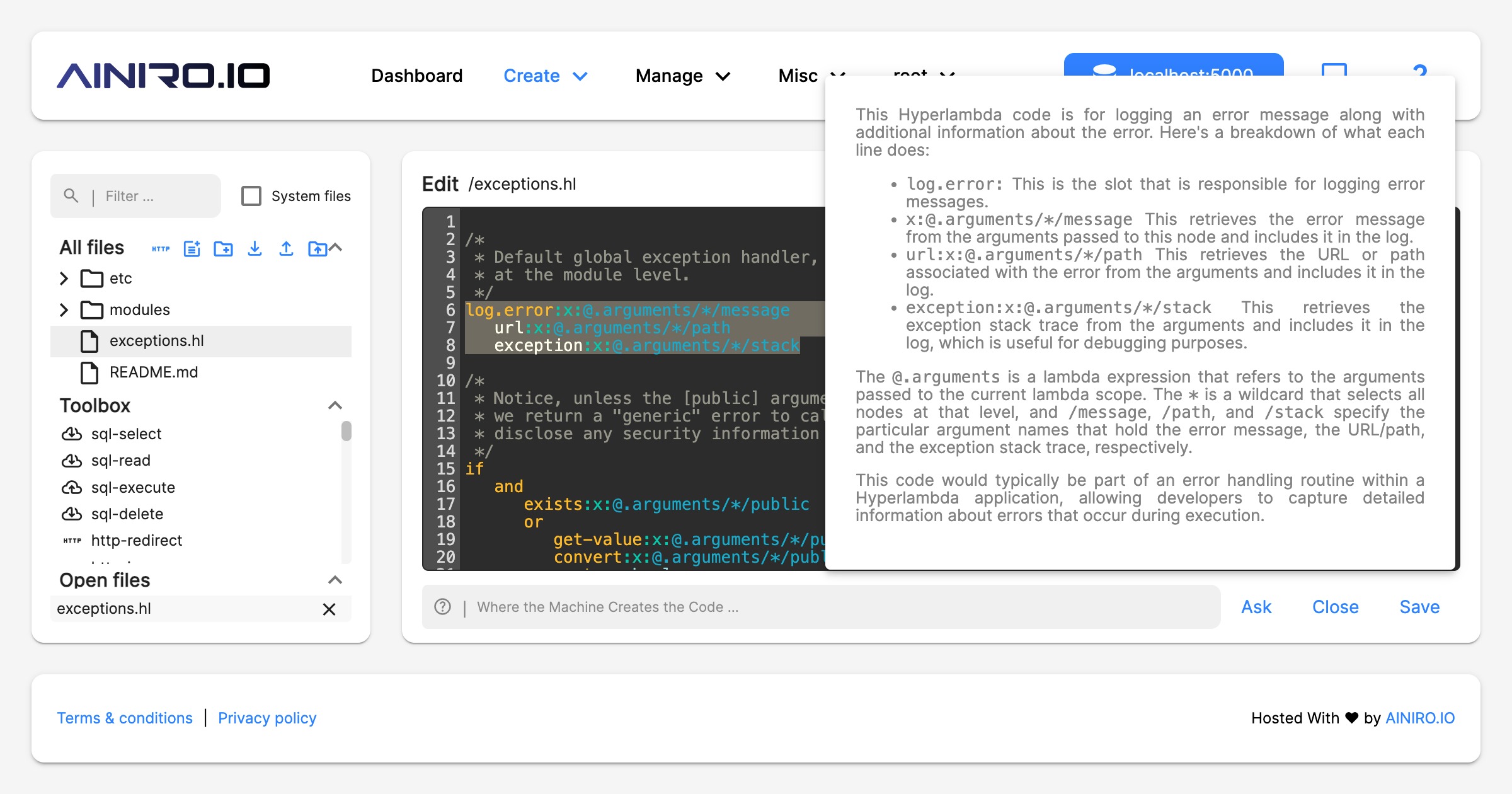
Magic’s machine learning component is actually horizontally implemented into almost every single component in Magic. Need to use AI from SQL Studio, no problem, it’s an integrated feature. The same is true for Hyper IDE, and even help is implemented using OpenAI and ChatGPT. If you need help with some Hyperlambda code, just mark it in Hyper IDE and click F1, which will use AI to explain what the code does.
However, in order to use machine learning with Magic, you will need an OpenAI API key. This will cost you some money, but OpenAI gives you a balance of 18 dollars initially.
Magic’s integrated support chatbot
In addition Magic integrates a support chatbot directly into its dashboard. This provides you with integrated help directly from the dashboard. Click the chat button in the top right corner in your dashboard to access this chatbot.
Magic’s integrated help system
Another crucial component related to machine learning in Magic is its integrated help system. If you’re in Hyper IDE and you don’t understand some snippet of Hyperlambda, you can mark this Hyperlambda, and click F1. This will use machine learning to explain the selected Hyperlambda for you.
Create your own AI chatbot
You can create your own ChatGPT based chatbot with Magic. To get the JavaScript needed to include your bot on your own website, only takes a couple of seconds, and can be done as you are configuring your machine learning model.
As long as you have a website where you can somehow add a JavaScript file, Magic will do the rest, associate your bot with your model, also your custom model, and render a chat window wrapping your own AI model for asking questions.
You can see an example of such a chatbot in the bottom/right corner of this page.
However, the easiest way to create your own chatbot is probably to start out with the Chatbot Wizard.